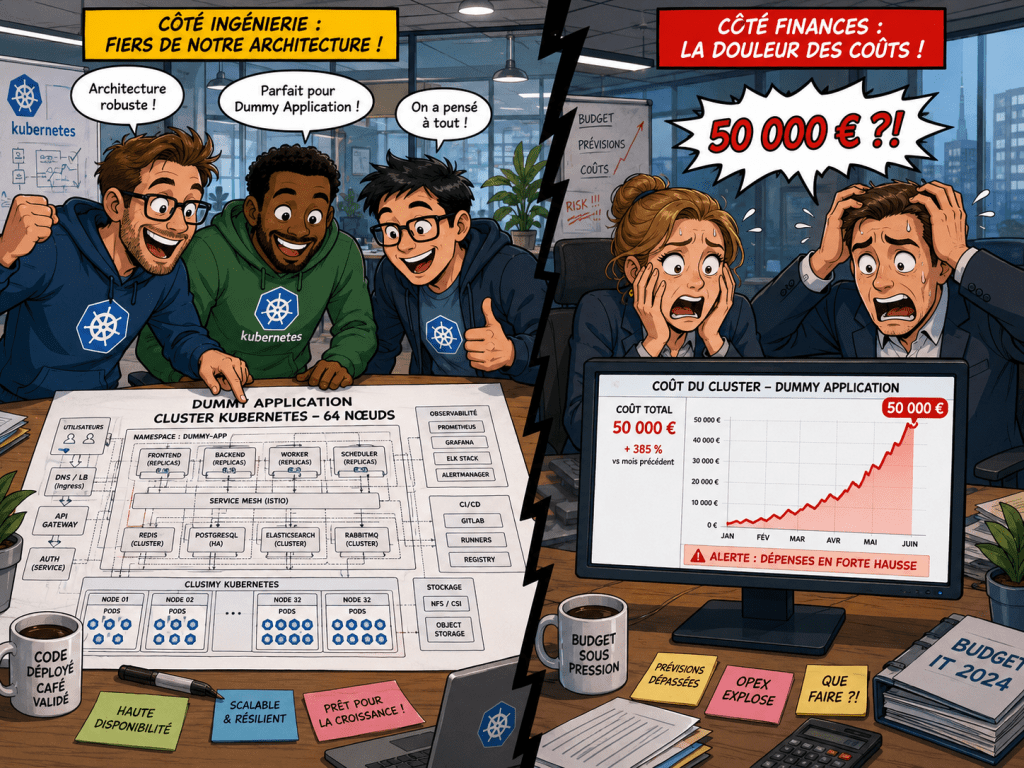
L’overengineering est un énorme problème dans la tech. Et souvent on en rigole, mais on devrait plutôt en pleurer.
Ça vous est déjà arrivé d’arriver sur une mission et de découvrir un énorme cluster Kubernetes tourner pour servir une infrastructure web tout ce qu’il y a de plus basique, avec quelques milliers de connexions par jour ? Ah c’est sûr, ça ronronnait, avec cinq serveurs dédiés 😆 Je précise que j’apprécie K8S, j’en critique uniquement le choix ici.
Même aventure avec un cluster ElasticSearch, une dizaine de noeuds montés aux petits oignons, prêts à recevoir les données de… quatre émetteurs envoyant des faibles flux de données de manière intermittente 😬 N’importe quelle solution 10 fois moins puissante répondrait mieux à ce besoin… sans l’overhead associé.
Les exemples sont légion. Mais la source est souvent la même. L’envie de monter une technologie particulière pour répondre à un besoin, certes, mais sans vraiment suffisamment s’intéresser précisément à ce besoin. Un architecte infrastructure ou solutions doit faire le choix d’une infrastructure avec un coût raisonnable et un investissement réfléchi des équipes technique pour répondre au besoin.
L’overengineering, c’est quasiment toujours des coûts supplémentaires et, peut-être encore plus cher sur le moyen terme, du temps humain gaspillé pour un gain difficilement discernable et justifiable. C’est aussi le meilleur moyen de toute refaire quelques temps après, quand on se rend compte que l’équipe n’est pas dimensionné pour gérer un mastodonte comme celui qu’on a mis en place…
L’auteur
Je suis architecte infrastructure cloud (AWS et Azure) senior freelance certifié AWS Solutions Architect Associate. Je conçois les infrastructures dont vous avez besoin pour faire tourner les services IT de vos entreprises et vous aide dans vos grands processus de migrations et de remédiations. Disponible pour une nouvelle mission. N’hésitez pas à me contacter si je peux vous aider dans vos projets.

Laisser un commentaire